llama.cpp Engine
llama.cpp is the core inference engine Jan uses to run AI models locally on your computer. This section
covers the settings for the engine itself, which control how a model processes information on your hardware.
Accessing Engine Settings
Section titled “Accessing Engine Settings”Find llama.cpp settings at Settings > Local Engine > llama.cpp:
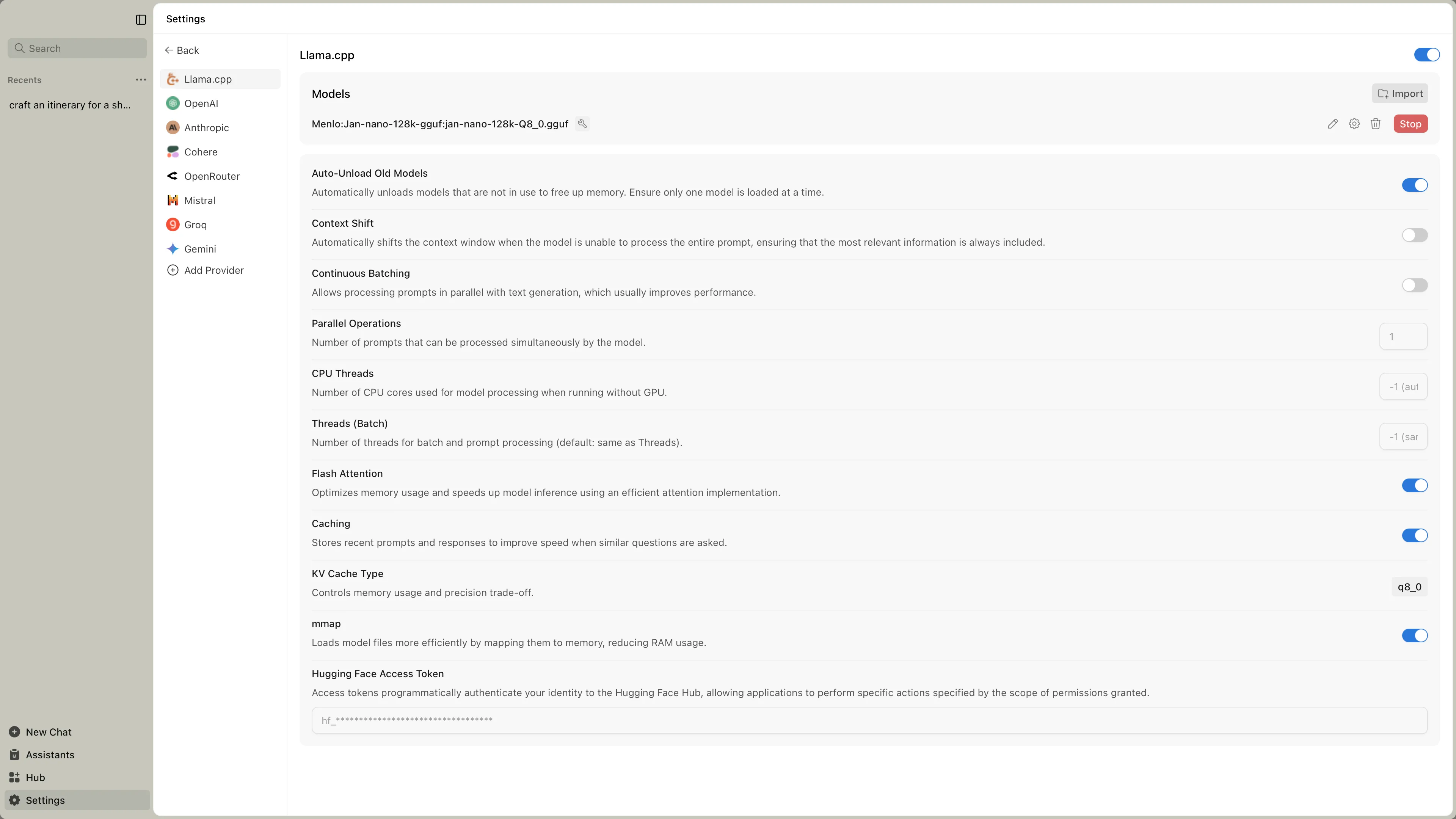
When to Adjust Settings
Section titled “When to Adjust Settings”You might need to modify these settings if:
- Models load slowly or don’t work
- You’ve installed new hardware (like a graphics card)
- You want to optimize performance for your specific setup
Engine Management
Section titled “Engine Management”| Feature | What It Does | When You Need It |
|---|---|---|
| Engine Version | Shows current llama.cpp version | Check compatibility with newer models |
| Check Updates | Downloads engine updates | When new models require updated engine |
| Backend Selection | Choose hardware-optimized version | After hardware changes or performance issues |
Hardware Backends
Section titled “Hardware Backends”Different backends are optimized for different hardware. Pick the one that matches your computer:
NVIDIA Graphics Cards (Fastest)
Section titled “NVIDIA Graphics Cards (Fastest)”For CUDA 12.0:
llama.cpp-avx2-cuda-12-0(most common)llama.cpp-avx512-cuda-12-0(newer Intel/AMD CPUs)
For CUDA 11.7:
llama.cpp-avx2-cuda-11-7(older drivers)
CPU Only
Section titled “CPU Only”llama.cpp-avx2(modern CPUs)llama.cpp-avx(older CPUs)llama.cpp-noavx(very old CPUs)
Other Graphics Cards
Section titled “Other Graphics Cards”llama.cpp-vulkan(AMD, Intel Arc)
NVIDIA Graphics Cards
Section titled “NVIDIA Graphics Cards”llama.cpp-avx2-cuda-12-0(recommended)llama.cpp-avx2-cuda-11-7(older drivers)
CPU Only
Section titled “CPU Only”llama.cpp-avx2(modern CPUs)llama.cpp-arm64(ARM processors)
Other Graphics Cards
Section titled “Other Graphics Cards”llama.cpp-vulkan(AMD, Intel graphics)
Apple Silicon (M1/M2/M3/M4)
Section titled “Apple Silicon (M1/M2/M3/M4)”llama.cpp-mac-arm64(recommended)
Intel Macs
Section titled “Intel Macs”llama.cpp-mac-amd64
Performance Settings
Section titled “Performance Settings”| Setting | What It Does | Recommended | Impact |
|---|---|---|---|
| Continuous Batching | Handle multiple requests simultaneously | Enabled | Faster when using tools or multiple chats |
| Parallel Operations | Number of concurrent requests | 4 | Higher = more multitasking, uses more memory |
| CPU Threads | Processor cores to use | Auto | More threads can speed up CPU processing |
Memory Settings
Section titled “Memory Settings”| Setting | What It Does | Recommended | When to Change |
|---|---|---|---|
| Flash Attention | Efficient memory usage | Enabled | Leave enabled unless problems occur |
| Caching | Remember recent conversations | Enabled | Speeds up follow-up questions |
| KV Cache Type | Memory vs quality trade-off | f16 | Change to q8_0 if low on memory |
| mmap | Efficient model loading | Enabled | Helps with large models |
| Context Shift | Handle very long conversations | Disabled | Enable for very long chats |
Memory Options Explained
Section titled “Memory Options Explained”- f16: Best quality, uses more memory
- q8_0: Balanced memory and quality
- q4_0: Least memory, slight quality reduction
Quick Troubleshooting
Section titled “Quick Troubleshooting”Models won’t load:
- Try a different backend
- Check available RAM/VRAM
- Update engine version
Slow performance:
- Verify GPU acceleration is active
- Close memory-intensive applications
- Increase GPU Layers in model settings
Out of memory:
- Change KV Cache Type to q8_0
- Reduce Context Size in model settings
- Try a smaller model
Crashes or errors:
- Switch to a more stable backend (avx instead of avx2)
- Update graphics drivers
- Check system temperature
Quick Setup Guide
Section titled “Quick Setup Guide”Most users:
- Use default settings
- Only change if problems occur
NVIDIA GPU users:
- Download CUDA backend
- Ensure GPU Layers is set high
- Enable Flash Attention
Performance optimization:
- Enable Continuous Batching
- Use appropriate backend for hardware
- Monitor memory usage